Final Example
Tying all this together, here is a computational linguistics program which analyses word usage in a text file, applied to the Project Gutenberg version of the complete works of Shakespeare:
#! /usr/bin/perl -w
use strict;
use Text::Wrap;
{
my ($sourceFile, $wordFile, $plotFile, $line, $contents, $word, $wordCount,
$totalCount, $vocabularyCount, $incrementalCount, $coverage, $frequency,
$i, $sortedWords, @words, @sortedWords, %index, %wordsByFrequency);
# open source file and store contents in a string
$sourceFile = 'shakespeare.txt';
open(SOURCE, "$sourceFile") or die("can't open $sourceFile");
while ($line = <SOURCE>) {
$contents .= $line;
}
close(SOURCE) or die "can't close $sourceFile";
# open analysis file and write header
$wordFile = 'words.txt';
open(WORDS, ">$wordFile") or die("can't open $wordFile");
print(WORDS "ANALYSIS OF \U$sourceFile\E\n\n");
# open plot file and write header
$plotFile = 'commands.gnuplot';
open(PLOT, ">$plotFile") or die("can't open $plotFile");
print(PLOT <<EOF);
set log y
set title "ANALYSIS OF \U$sourceFile\E"
set xlabel "word coverage"
set ylabel "most frequent words"
set term postscript color
set out "plot.ps"
plot '-' with lines
EOF
# compact file and count words
@words = ();
$contents =~ s/-/ /g; # replace hyphens with spaces
while ($contents =~ m/([^\s]+)/g) { # extract space-separated words
$word = $1; # must copy $1!
if (($word !~ m/[A-Z][A-Z]+/g) && # don't match eg 'LEAR'
($word !~ m/^[A-Z]+\.$/)) { # don't match eg 'Lear.'
$word =~ s/^\W+//; # strip leading 0
$word =~ s/\W+$//; # strip trailing punctuation
$word =~ s/'.*$//; # strip everything after an apostrophe
push(@words, $word);
}
}
$totalCount = scalar(@words);
print(WORDS "Total word count = $totalCount\n\n");
# make word index
%index = ();
for ($i = 0; $i < $totalCount; $i++) {
$words[$i] = "\l$words[$i]"; # lower case first character
if (($words[$i] !~ m/_/) && # no underscores
($words[$i] !~ m/\d/)) { # no digits
push(@{$index{$words[$i]}}, $i);
}
}
$vocabularyCount = scalar(keys(%index));
print(WORDS "Vocabulary count = $vocabularyCount\n\n");
# make inverted word index
%wordsByFrequency = ();
foreach $word (keys %index) {
$frequency = scalar(@{$index{$word}});
push(@{$wordsByFrequency{$frequency}}, $word);
}
# record word usage
$coverage = 0;
$incrementalCount = 0;
print(WORDS "Key: [incremental count] (word frequency) {word count}\n\n");
foreach $frequency (sort reverseNumeric keys(%wordsByFrequency)) {
@sortedWords = sort(@{$wordsByFrequency{$frequency}});
$sortedWords = wrap('', '', join(' ', @sortedWords));
$wordCount = scalar(@sortedWords);
$incrementalCount += $wordCount;
$coverage += $wordCount*$frequency/$totalCount;
print(WORDS "[$incrementalCount] ($frequency) {$wordCount}:\n");
print(WORDS "$sortedWords\n\n");
print(PLOT "$coverage $incrementalCount\n");
}
print(PLOT "e\n");
close(WORDS) or die("can't close $wordFile");
close(PLOT) or die("can't close $plotFile");
system("gnuplot $plotFile") or die("can't execute gnuplot");
}
# sub numeric:
# For numeric sorting. Normal sorting is ascii. Usage 'sort numeric @list;'.
sub numeric ()
{
$a <=> $b;
}
# sub reverseNumeric:
# For reverse numeric sorting (highest number first). Normal sorting is ascii.
# Usage 'sort reverseNumeric @list;'.
sub reverseNumeric ()
{
$b <=> $a;
}
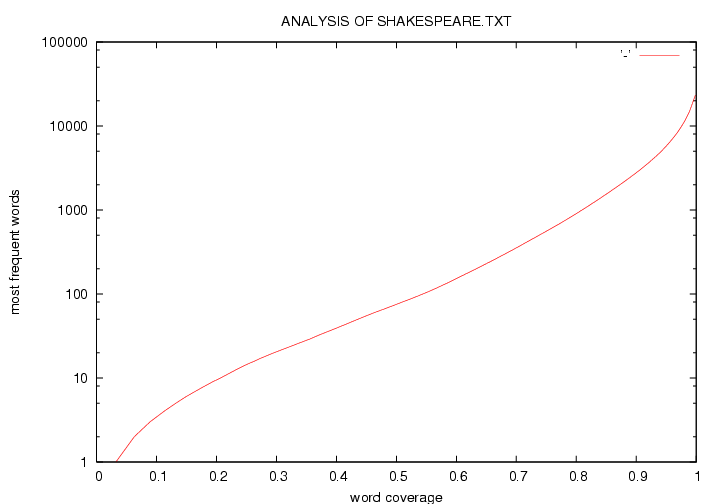
The program generates an analysis of word usage and the following word coverage plot. It takes 7 seconds to process the 5Mb source file on my 64-bit Linux system at home.